Introduction to Bismuth VM
This is the first post in what will hopefully become a series of posts about a virtual machine I’m developing as a hobby project called Bismuth. This post will touch on some of the design fundamentals and goals, with future posts going into more detail on each.
But to explain how I got here I first have to tell you about Bismuth, the kernel.
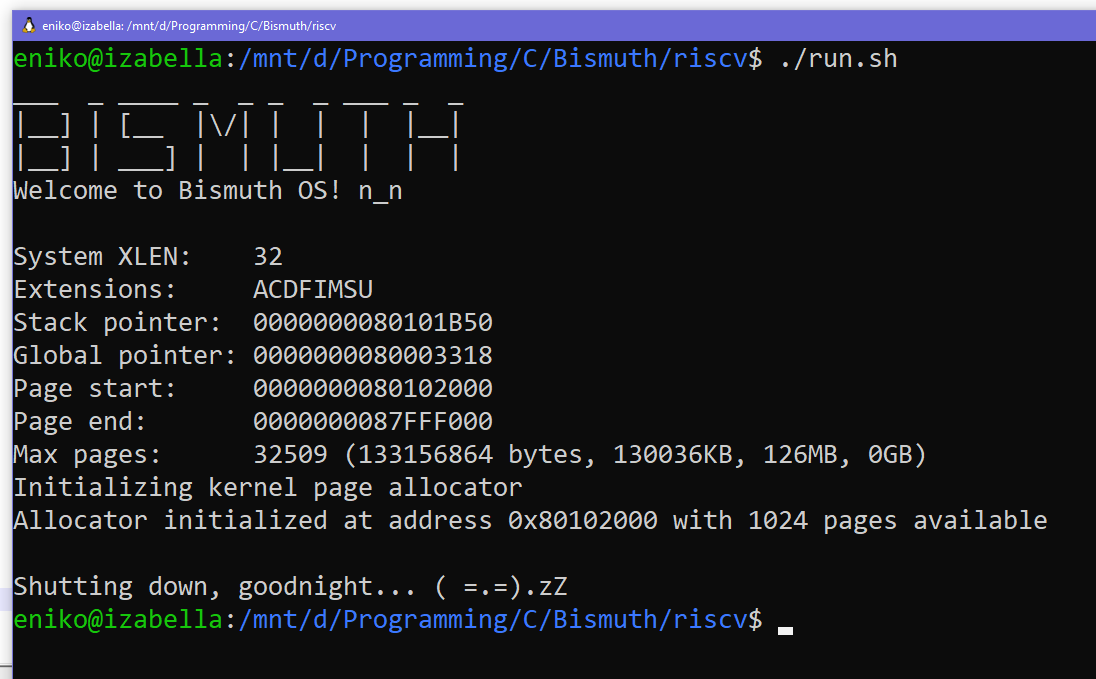
Bismuth OS
Over my winter holiday break at the end of 2023 I was doing some recreational OS development. I was working on a kernel called Bismuth (Bismuth OS) running on 32-bit or 64-bit RISC-V and got as far as having a 4k kernel page allocator. At that point it was time to deal with virtual memory mapping and the MMU. I wasn’t feeling up to that sort of commitment and my break ended and life and work resumed.
At various points throughout 2024 I had the urge to pick the project back up, but dealing with memory mapping prevented me from doing so. I investigated running position independent executables, but the details of compiling executables to be position independent felt even more tiresome. It felt like there was no good, fun way to pick the project back up.
Eventually though, a thought hit me: what if the kernel just runs a virtual machine? That VM could run programs, those programs could be position independent, and the VM could ensure that no program steps on memory owned by another program. That’s how Bismuth (Bismuth VM) was born.
DDCG
The idea for this VM didn’t come out of nowhere though. A friend of mine who’d been working on a Gameboy Z80 compiler for his own language had introduced me to Destination-Driven Code Generation. DDCG is a technique for generating machine code from an abstract syntax tree, or AST, that is conceptually a lot simpler than other approaches which require things like SSA (static single assignment), phi nodes, and register allocation. He’d learned about DDCG from this blog post written by Max Bernstein. I assume Max learned about it from the paper by R. Kent Dybvig from Indiana University written in the extremely recent year of *checks notes* 1990.
So, yeah, maybe DDCG isn’t the latest and greatest, but given that three people have been diving into it in the past year or so, maybe we can say it’s having a bit of a revival? Plus it can’t be utterly hopeless, as evidenced by this slide deck for a talk by Kevin Millikin about how Google’s V8 scripting engine used to use it. I can’t source the date on that one, and it may be 15 years old for all I know, but if it was ever good enough for Google it’s good enough for me!
In essence the trick behind DDCG is that in an abstract syntax tree a parent node will have contextual information that will help remove redundant operations if the child is informed. As a trivial example, in the expression x + 1 the immediate value 1 would be a node of its own. It would know that an constant value of 1 is supposed to go somewhere, but it doesn’t have the context required to know where. A simple way to deal with this is to generate code that pushes 1 onto the stack in the child node, and then pop that into a register after. The code might look something like this:
; put the value 1 in a register, then push to stack
MOV X 1
PUSH X
; pop the result of child expression into register X
POP X
This is kind of like implementing a stack machine on top of a register machine, and it’s a bit silly isn’t it? The parent already knows to put 1 into register X. If we could just tell the child that the destination register should be X, we could get away with just one MOV X 1 operation. Fortunately, we can! In DDCG you pass the destination register down to child nodes, and then they “plug” the result of the operation into the correct register. In fact, the destination can be a register, the stack, or it could even be discarded.
If you want to learn more about it, I highly recommend you read Max’s article about DDCG.
The big benefit of DDCG is that you don’t have to worry about lowering your code to basic blocks using static single assignment. You can operate directly on the AST you get from your parser which cuts out a lot of the complexity. The other benefit is that it’s fast which means that you can use it for JIT compilation as well. In fact from what I understand DDCG normally would be used for JIT compilation, where speed is a lot more important than optimal efficiency.
Intermediate representation
Making programming languages is hard and the more you can separate concerns, the better off you’ll be. To that end I made a decision a few years ago that I would separate my programming language development projects into two separate parts:
- A simple intermediate representation in AST form which can be compiled to bytecode, machine code, or even transpiled to C.
- The actual language with all of the expected syntax features which sits on top of and compiles to this IR.
Storing programs in the form of an AST happens to be exactly what DDCG needs in order to emit byte or machine code. This is not unlike the model used by webassembly, which also stores its IR as an AST in a binary file, with other languages compiling to that IR. In fact, I stole the idea of using s-expressions for my IR from webassembly’s WAT plain-text format, although I’m a little bit more strict on the parentheses than they seem to be.
The benefit of this approach means that if the IR isn’t working out I can dump the project long before I need to waste any time on complex lexing, parsing, and error recovery mechanisms. Plus if the IR is sound but the language that sits on top of it isn’t I can scrap the high-level language and create a new one that targets the IR without having to start completely from scratch. The tools that take the IR and transform it to something else are fully independent and will continue working fine, after all.
Currently, Bismuth’s IR (in plain-text form) looks something like this:
(func fib (n) {
(if (lte n 1) {
(ret n)
} {
(ret (add (call fib (sub n 1)) (call fib (sub n 2))))
})
})
Every value in the VM is currently a 32-bit integer, and all operations work only on those. This is to keep the IR as absolutely simple as possible. It’s also, again, a lot like webassembly, although that distinguishes between 32-bit and 64-bit integer operations and also has support for floating point.
The IR is extremely easy to parse because it’s Lisp-like. Also, the IR isn’t supposed to be written in plain-text by hand so I don’t have to waste a lot of time on proper syntax error detection. So with this IR and DDCG the VM can start by interpreting bytecode, and can then use a JIT compilater to emit and run machine code for hot paths.
Design goals
So what are my design goals for Bismuth VM? I’m a game developer by trade and that’s going to influence the types of things I’d want to make with my own languages, and the design of those languages. I’ll detail my design goals for this VM in the sections below.
Must be fast (have JIT or AOT compilation)
Really this “fast” is more of a “fast-ish” as I’m not looking for the ultimate in performance. I’m just looking for something faster than your average interpreted language because making games using fully interpreted languages is painful in the performance department. I massively respect the Lua team for making such a fast register-machine interpreter, but it’s still not enough for me.
The VM has to be able to optimize code somehow, whether it be through JIT compilation, AOT compilation, or even transpiling to another language with an optimizing compiler. Fortunately DDCG can do both JIT and AOT compilation, if you’re not too fussed about the quality of the machine code. The AST can also be transpiled to C because…
The IR must be compatible with standard C (without compiler-specific extensions)
If the IR is sufficiently like C then transpiling from the abstract syntax tree to C becomes almost (but not entirely, as we’ll see in a future post) trivial. C is the most portable language in the world, and I’m pretty comfortable with it. This means programs written for the VM could also be transpiled to C and then compiled to a stand-alone executable with an optimizing compiler like GCC to get as much performance as possible. This is a great ace up your sleeve to have for games!
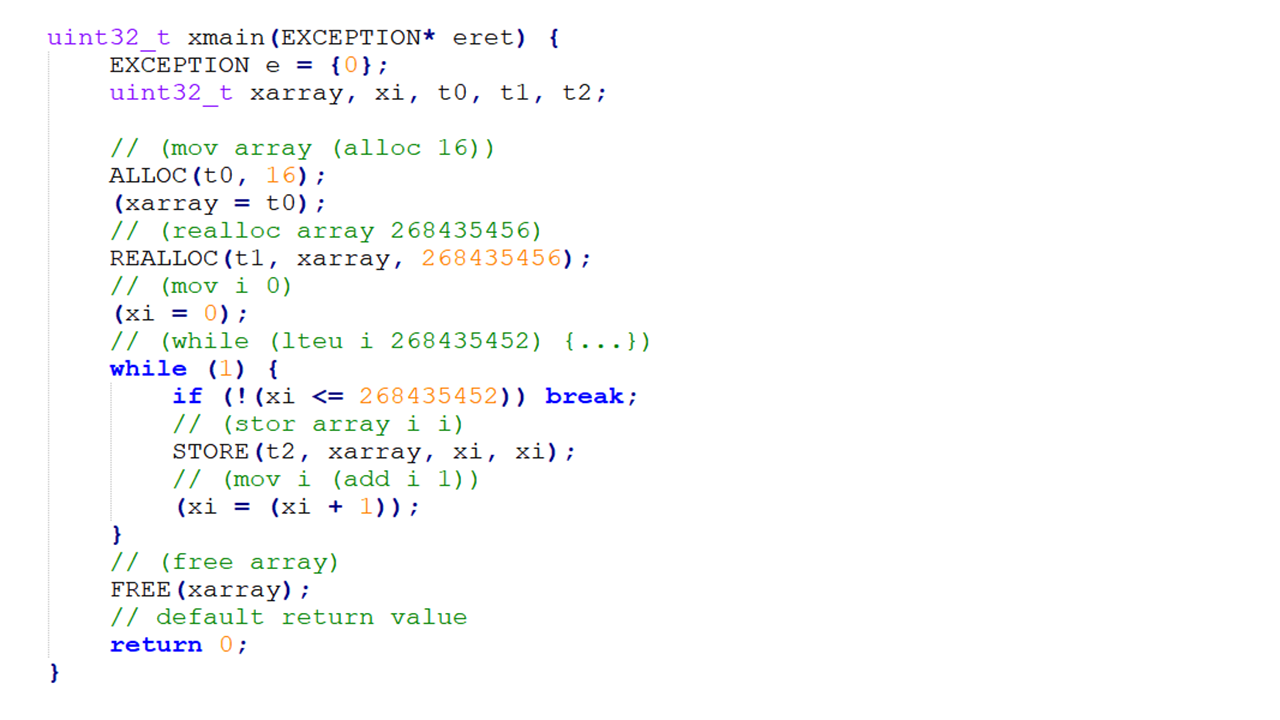
Since the VM is written in C, this means that if I play my cards right large parts of the VM can be written using the VM’s IR and transpiled to C and integrated into the VM. I plan for Bismuth to have system calls which do game-development type things that you would expect from a batteries included environment like QBASIC or fantasy consoles like Pico-8 or TIC-80. By writing these routines in the IR (or a language that targets it) this standard library of system calls would be very portable. Also, they could be more easily integrated with standalone executables.
Another benefit of transpiling to C means that web support becomes possible because C can compile to webassembly, and that…
Can run in a browser
Running a VM (Bismuth) inside another VM (the browser’s webassembly sandbox) just doesn’t perform well, especially since it greatly complicates having a functioning JIT compiler. Programs written for Bismuth should be able to be ahead-of-time compiled to webassembly so they can run standalone in a browser, without the overhead of the actual VM. This requires the IR be largely compatible with webassembly, or at the very least for the IR to be transpilable to C.
And last but not least…
The VM must be easy to implement
Making a VM too hard to implement hinders portability. Webassembly got this right initially, with a relatively sleek and minimal design. Then they started to heap a bunch of hard-to-implement extensions on top of that which, if you ask me, was the wrong call. VMs aren’t conceptually very complex: churning through some bytecode and interpreting each individual operation is pretty easy, and I don’t want to overcomplicate things. This means I want to keep Bismuth (the specification) easy to replicate. If someone wants or needs to roll their own implementation of the VM, it shouldn’t take months or even years to do.
This impacts a lot of the design of the VM, but especially memory management as we’ll see in a future post.
Writing large parts of the VM in its own IR also means those parts of the VM can be compiled to bytecode instead of C in order to bootstrap a new implementation of the VM. The whole standard library doesn’t have to be reimplemented, it can simply be interpreted.
Sounds cool, but how much of this have you got working?
Great question, reader! At the time of writing I’ve got the following working:
- Plain-text IR and compiler supporting functions with arguments, locals and return values, if/else, while loops, function calls, all the usual operators, memory management, load/store, and even logical and/or
- Human-readable binary version of the IR
- A VM written in C that ingests the binary IR and processes it using DDCG into bytecode which it runs
- A transpiler which takes the plain-text IR and converts it to equivalent C code
I’ve also got a first draft of an error handling model planned out, and am working on a language that compiles to the VM’s IR.
Will all of this ever amount to something usable? Who knows! I’m not even sure I’m still developing this VM for my RISC-V kernel at this point. I’ve also never gotten anywhere with my hobby language development projects before, but it’s not impossible this is the one.
Either way, I intend to write more posts covering work I’ve already done. These will include such topics as compilation using DDCG in more depth and some new tricks I’ve learned while using it, the error handling model I’ve settled on, the specifics of transpiling from C-like IR to C (it’s more complex than you might think!) and the memory management and safety aspects of the VM.
Those categories are in arbitrary order. I’m not making any promises as to when or in what order I’ll cover these topics. Still, if you’ve read this all the way to the end, then I hope you’ll join me again next time on this programming language development journey.